[spark] 배치 프로세싱
RDD
- 스파크의 기본 추상화 객체
주요 구성 요소
- 의존성 정보
어떤 입력을 필요로 하고, 현재 RDD가 어떻게 만들어지는지
새로운 결과를 만들어야 하는 경우, 스파크는 이 의존성 정보를 참고하고 연산을 재반복해 RDD를 재생성할 수 있음
- 파티션
- 스파크에서 작업을 실행기들에 분산하여 파티션 별로 병렬 연산할 수 있도록 함
- **연산 함수: **
**Partition => Iterator[T]**- RDD에 저장되는 데이터를 반복자 형태로 변환
RDD API의 문제점
- Spark는 RDD API 기반의 연산, 표현식을 검사하지 못해 최적화할 방법이 없음
Join, filter, group by 등 여러 연산을 하더라도 spark에서는 람다 표현식으로만 보임
특히 Pyspark의 경우, 연산 함수
Iterator[T]데이터 타입을 제대로 인식하지 못함. 단지 파이썬 기본 객체로만 인식 (python이 java/scala와는 달리 타입이 없는 언어이기 때문)
- Spark는 어떠한 데이터 압축 테크닉도 적용하지 못함
제네릭 형태로 표현한 타입 T에 대한 정보를 전혀 얻을 수 없음
그 타입의 객체 안에서 어떤 타입의 컬럼에 접근한다고 해도, spark는 알 수 없음
결국 byte 뭉치로 직렬화해서 사용할 수 밖에 없음
→ Spark가 연산 순서를 재정렬해 개발자가 작성한 쿼리 대비 효과적인 질의 계획으로 바꿀 수 없음
SparkSQL
구조화된 데이터를 처리하기 위한 스파크 모듈
DataFrame, Dataset이라 불리는 추상화를 제공하고, 분산 SQL 쿼리 엔진의 역할도 수행
위에서 언급한 RDD의 문제점들을 해결할 수 있음
역할
SQL같은 질의 수행
spark 컴포넌트 통합
DataFrame, Dataset이 여러 프로그래밍 언어로 정형화 데이터 관련 작업을 단순화할 수 있도록 추상화해줌
- 정형화된 파일 포맷(JSON, CSV, txt, avro, parqueet, orc 등)에서 스키마와 정형화 데이터를 읽고 쓰며, 데이터를 임시 테이블로 변환
- RDD만 사용할 경우 → txt / sequence file 등 기본적인 형태의 파일만 제공됨
빠른 데이터 탐색을 위해 대화형 Spark SQL Shell 제공
- 표준 데이터베이스 JDBC/ODBC 커넥터를 통해 외부 도구와 연결할 수 있는 중간 역할 제공
- Tableau / Snowflake / Power BI / Databricks 등 여러 애플리케이션과 쉽게 연결
- 최종 실행을 위해 최적화된 질의 계획과 JVM을 위한 최적화된 코드 생성
장점
- 성능
- RDD와 달리 연산, 표현식, 데이터 타입 정보를 모두 알 수 있음 → 연산 순서를 재정렬해 더 효과적인 질의 계획을 변경 가능
- 카탈리스트 옵티마이저
- 연산 쿼리를 받아 실행 계획으로 변환. 크게 아래 4단계의 변환 과정을 거쳐 RDD 생성
분석
논리적 최적화
물리 계획 수립
코드 생성
- 연산 쿼리를 받아 실행 계획으로 변환. 크게 아래 4단계의 변환 과정을 거쳐 RDD 생성
- 표현성
- RDD에서 사용하는 람다 표현식보다 DataFrame API 메서드는 무엇을 하고자 하는지 명확하게 보임
- 일관성
- python/java/scala 등 여러 언어로 작성한 스파크 코드의 형태가 거의 비슷함
Dataframe API
pandas의 dataframe의 영향을 많이 받음
컬럼과 스키마를 가진 분산 인메모리 테이블처럼 동작
스키마
Dataframe을 위해 컬럼 이름과 데이터 타입을 정의한 것
외부 데이터 소스에서 구조화된 데이터를 읽어올 때 사용
읽을 때 스키마를 가져오는 방식과 달리, 미리 스키마를 정의하는 것은 여러 장점이 존재
스파크가 데이터 타입을 추측해야 하는 책임을 덜어줌
스파크가 스키마를 확정하기 위해서 파일의 많은 부분을 읽어들이려고 별도의 job을 만드는 것을 방지
데이터가 스키마에 맞지 않는 경우를 조기에 발견할 수 있음
스키마 정의 방법
- 프로그래밍 스타일
1
2
3
schema = StructType([StructField("author", StringType(), False),
StructField("title", StringType(), False),
StructField("pages", StringType(), False), ])
- DDL
1
schema = "author STRING, title STRING, pages INT"
Explain
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
== Parsed Logical Plan ==
'Sort ['hour ASC NULLS FIRST, 'minute ASC NULLS FIRST], true
+- Aggregate [hour#47, minute#48], [hour#47, minute#48, collect_set(ip#0, 0, 0) AS ip_list#49, count(ip#0) AS ip_count#50L]
+- Project [ip#0, timestamp#33, method#2, endpoint#3, status_code#4, latency#5, latency_seconds#32, hour#47, minute(date_trunc(minute, timestamp#33, Some(Asia/Seoul)), Some(Asia/Seoul)) AS minute#48]
+- Project [ip#0, timestamp#33, method#2, endpoint#3, status_code#4, latency#5, latency_seconds#32, hour(date_trunc(hour, timestamp#33, Some(Asia/Seoul)), Some(Asia/Seoul)) AS hour#47]
+- Project [ip#0, to_timestamp(timestamp#1, None, TimestampType, Some(Asia/Seoul), true) AS timestamp#33, method#2, endpoint#3, status_code#4, latency#5, latency_seconds#32]
+- Project [ip#0, timestamp#1, method#2, endpoint#3, status_code#4, latency#5, (cast(latency#5 as double) / cast(1000 as double)) AS latency_seconds#32]
+- Relation [ip#0,timestamp#1,method#2,endpoint#3,status_code#4,latency#5] csv
== Analyzed Logical Plan ==
hour: int, minute: int, ip_list: array<string>, ip_count: bigint
Sort [hour#47 ASC NULLS FIRST, minute#48 ASC NULLS FIRST], true
+- Aggregate [hour#47, minute#48], [hour#47, minute#48, collect_set(ip#0, 0, 0) AS ip_list#49, count(ip#0) AS ip_count#50L]
+- Project [ip#0, timestamp#33, method#2, endpoint#3, status_code#4, latency#5, latency_seconds#32, hour#47, minute(date_trunc(minute, timestamp#33, Some(Asia/Seoul)), Some(Asia/Seoul)) AS minute#48]
+- Project [ip#0, timestamp#33, method#2, endpoint#3, status_code#4, latency#5, latency_seconds#32, hour(date_trunc(hour, timestamp#33, Some(Asia/Seoul)), Some(Asia/Seoul)) AS hour#47]
+- Project [ip#0, to_timestamp(timestamp#1, None, TimestampType, Some(Asia/Seoul), true) AS timestamp#33, method#2, endpoint#3, status_code#4, latency#5, latency_seconds#32]
+- Project [ip#0, timestamp#1, method#2, endpoint#3, status_code#4, latency#5, (cast(latency#5 as double) / cast(1000 as double)) AS latency_seconds#32]
+- Relation [ip#0,timestamp#1,method#2,endpoint#3,status_code#4,latency#5] csv
== Optimized Logical Plan ==
Sort [hour#47 ASC NULLS FIRST, minute#48 ASC NULLS FIRST], true
+- Aggregate [hour#47, minute#48], [hour#47, minute#48, collect_set(ip#0, 0, 0) AS ip_list#49, count(ip#0) AS ip_count#50L]
+- Project [ip#0, hour(date_trunc(hour, timestamp#33, Some(Asia/Seoul)), Some(Asia/Seoul)) AS hour#47, minute(date_trunc(minute, timestamp#33, Some(Asia/Seoul)), Some(Asia/Seoul)) AS minute#48]
+- Project [ip#0, cast(timestamp#1 as timestamp) AS timestamp#33]
+- Relation [ip#0,timestamp#1,method#2,endpoint#3,status_code#4,latency#5] csv
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- Sort [hour#47 ASC NULLS FIRST, minute#48 ASC NULLS FIRST], true, 0
+- Exchange rangepartitioning(hour#47 ASC NULLS FIRST, minute#48 ASC NULLS FIRST, 200), ENSURE_REQUIREMENTS, [plan_id=36]
+- ObjectHashAggregate(keys=[hour#47, minute#48], functions=[collect_set(ip#0, 0, 0), count(ip#0)], output=[hour#47, minute#48, ip_list#49, ip_count#50L])
+- Exchange hashpartitioning(hour#47, minute#48, 200), ENSURE_REQUIREMENTS, [plan_id=33]
+- ObjectHashAggregate(keys=[hour#47, minute#48], functions=[partial_collect_set(ip#0, 0, 0), partial_count(ip#0)], output=[hour#47, minute#48, buf#64, count#65L])
+- Project [ip#0, hour(date_trunc(hour, timestamp#33, Some(Asia/Seoul)), Some(Asia/Seoul)) AS hour#47, minute(date_trunc(minute, timestamp#33, Some(Asia/Seoul)), Some(Asia/Seoul)) AS minute#48]
+- Project [ip#0, cast(timestamp#1 as timestamp) AS timestamp#33]
+- FileScan csv [ip#0,timestamp#1] Batched: false, DataFilters: [], Format: CSV, Location: InMemoryFileIndex(1 paths)[file:/Users/bokyung/spark-streaming-study/02_batch/data/log.csv], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<ip:string,timestamp:string>
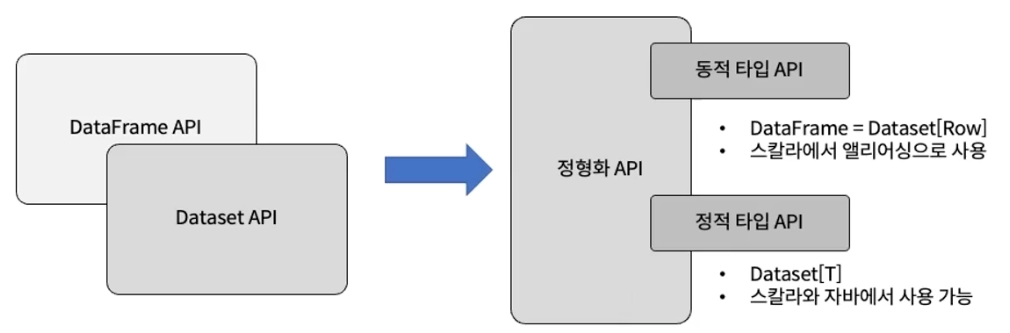
Dataset API
Spark 2.0에서 Datafram + Dataset API를 하나로 통합함
Dataset은 정적 타입 API와 동적 타입 API의 두 특성을 모두 가짐
Dataset은 Java, Scala에서만 사용 가능 (타입 안전을 보장하는 언어)
- Python, R은 타입 안전을 보장하지 않는 언어이기 때문에 사용 불가능