[spark] spark 살펴보기
spark
- 대규모 분산 데이터 처리를 하기 위해 설계된 통합형 엔진
설계 철학
- 속도
맵리듀스와 달리, 중간 결과를 메모리에 유지하기 때문에 훨씬 더 빠른 속도로 같은 작업 수행 가능
질의 연산을 방향성 비순환 그래프 (DAG)로 구성 1. DAG의 스케줄러와 질의 최적화 모듈 → 효율적인 연산 그래프 생성, 그래프를 각각의 태스크로 분해하여 클러스터의 워커 노드 위에서 병렬 실행될 수 있도록 함
텅스텐이라는 물리적 실행 엔진이 전체 코드를 재생성 (실행을 위한 간결한 코드)
- 사용 편리성
추상화가 잘 되어있음
Dataframe, Dataset과 같은 고수준 데이터 추상화 계층 아래에 RDD라는 단순한 자료구조를 구축해 단순성을 실현함
단순한 프로그래밍 모델 제공 (transformation, action)
여러 프로그래밍 언어 제공 (Scala, Java, Python 등)
- 모듈성
내장된 다양한 컴포넌트로 다양한 타입의 워크로드에 적용 가능 (SparkSQL, Structured Streaming, MLlib 등)
- 특정 워크로드를 처리하기 위해 하나의 통합된 처리 엔진을 가짐 1. 맵리듀스의 경우 배치 워크로드에는 적합하나, SQL 질의, 스트리밍, 머신러닝 등 다른 워크로드와 연계해 사용하기엔 어려움
1
2
3
2. 위와 같은 경우, 하둡과 함께 Apache Hive (SQL 질의), Storm (스트리밍), Mahout (머신러닝) 등 다른 시스템과의 연동 필요
3. 스파크를 사용한다면 배치/스트리밍/머신러닝 모두 스파크라는 하나의 프레임워크에서 해결이 가능하고, 코드도 크게 다르지 않기 때문에 모듈성이 높다고 볼 수 있음
- 확장성
저장과 연산을 모두 포함하는 하둡과는 달리, 스파크는 빠른 병렬 연산에만 초점을 맞춤
수많은 데이터 소스로부터 데이터를 읽어들일 수 있음
여러 파일 포맷과 호환 가능
- 이 외에 많은 서드파티 패키지 목록 사용 가능
애플리케이션 구성 요소
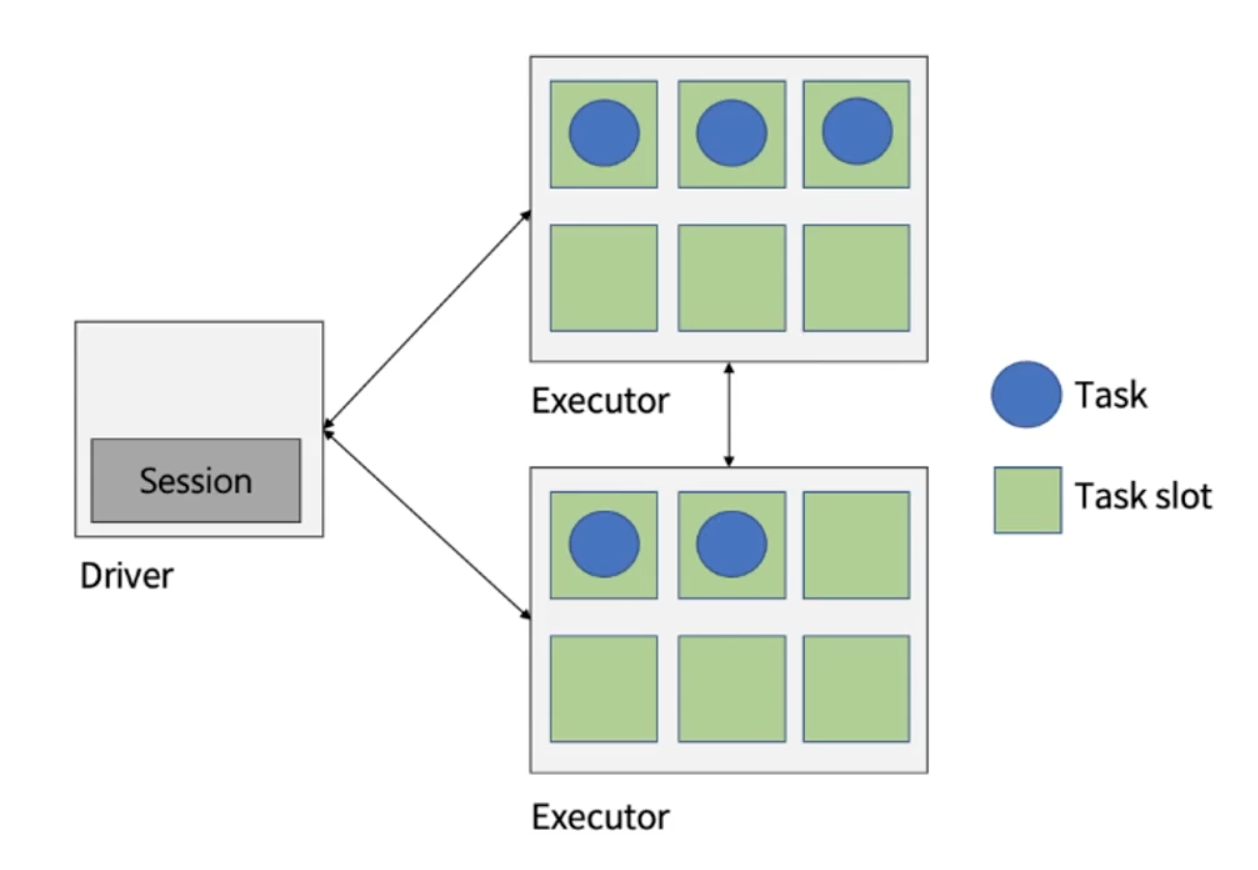
클러스터 매니저 (Cluster Manager)
- 전체 애플리케이션의 리소스 관리
드라이버가 요청한 실행기 프로세스 시작
실행 중인 프로세스 중지 / 재시작
실행자 프로세스가 사용할 수 있는 최대 CPU 코어 개수 제한 등
- 종류
Standalone (← local)
Apache Mesos
Hadoop Yarn
Kubernetes
드라이버 (Driver)
- 스파크 애플리케이션의 실행 관장 & 모니터링
클러스터 매니저에 메모리 및 CPU 리소스 요청
애플리케이션 로직을 스테이지와 태스크로 분할
여러 실행자에 태스크 전달
태스크 실행 결과 수집
1개의 스파크 애플리케이션에는 1개의 드라이버만 존재
- 드라이버 프로세스의 위치에 따라 2가지 모드가 존재
클러스터 모드: 드라이버가 클러스터 내의 특정 노드에 존재
클라이언트 모드: 드라이버가 클러스터 외부 (별도 pc/외부 서버)에 존재
실행기 (Executor)
드라이버가 요청한 태스크들을 받아서 실행하고, 결과를 드라이버로 반환
각 실행기는 JVM 프로세스
- 각 프로세스는 태스크들을 여러 태스크 슬롯 (스레드)에서 병렬로 실행
스파크 세션 (Session)
스파크 코어 기능들과 상호 작용할 수 있는 진입점 제공, 그 API로 프로그래밍을 할 수 있게 해주는 객체
spark-shell 에서는 기본적으로 제공
스파크 애플리케이션에서는 사용자가
SparkSession객체를 생성해 사용해야 함
잡 (Job)
스파크 액션 (
save(),collect()등) 에 대한 응답으로 생성되는 여러 태스크로 이루어진 병렬 연산job을 구분하는 기준이 action. (action이 수행이 되어야 transformation이 실행됨)
스테이지 (Stage)
각 Job은 스테이지라고 불리는 서로 의존성을 갖는 다수의 태스크 모음으로 나뉨
스테이지를 나누는 기준: Wide Transformation
- 각 실행기들끼리 데이터 교환이 발생
태스크 (Task)
각 Job 별 실행기로 보내지는 작업 할당의 가장 기본적인 단위
개별 태스크 슬롯에 할당되고, 데이터의 개별 파티션을 가지고 작업
- 1개의 태스크가 기본적으로 1개의 파티션을 가지고 transformation 연산을 수행함
Spark 연산더
Transformation
- 불변인 원본 데이터를 수정하지 않고, 하나의 RDD / Dataframe을 새로운 RDD / Dataframe으로 변형
RDD → RDD / DF → DF
map(),filter(),flatMap(),select(),groupby(),orderby()등
- 종류
- Narrow
input: 1개의 파티션
output: 1개의 파티션
파티션 간의 데이터 교환이 발생하지 않음
filter(),map(),coalesce()
- Wide
연산 시 파티션 간의 데이터 교환이 발생함
groupby(),orderby(),sortByKey(),reduceByKey()단, join의 경우 두 부모 RDD/DF가 어떻게 파티셔닝 되어있냐에 따라 narrow일 수도, wide일 수도 있음
- Narrow
Action
- 불변인 Input에 대해 Side Effect를 포함하고, output이 RDD 또는 Dataframe이 아닌 연산
- Side Effect: I/O 발생 등
- ex
count()→ intcollect()→ arraysave()→ void
Lazy Evaluation
모든 transformation은 즉시 계산되지 않고 lineage라고 불리는 형태로 기록됨
실제 계산되는 시점은** action이 실행되는 시점**
action이 실행될 때, 그 전까지 기록된 모든 transformation의 지연 연산이 수행됨
장점
스파크가 연산 쿼리를 분석하고, 어디를 최적화할지 파악하여 실행 계획 최적화 가능
장애에 대한 데이터 내구성 제공
- 장애 발생 시, 스파크는 기록된 리니지를 재실행하는 것만으로 원래 상태를 재생성할 수 있음